原始的GAN的原理
假设我们有两个网络,G(Generator)和D(Discriminator)。它们的功能分别是:
G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。 最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5 这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
这个过程可以用以下公式来表示:
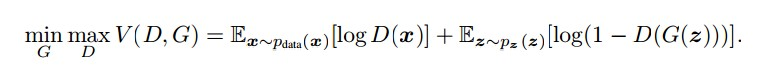
简单分析一下这个公式: 整个式子由两项构成。
x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。 而D(G(z))是D网络判断G生成的图片的是否真实的概率。
G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。 因此我们看到式子的最前面的记号是min_G。
D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大max_D
研究和使用过的gan网络
1, pix2pix
2, pix2pixHD
3, stylegan
4, stylegan2