pix2pix的一个记录:
1,原理
2,网络结构
3,loss设计
4,优缺点评论
原理:
pix2pix,是将GAN应用于有监督的图像到图像翻译的经典算法,有监督表示训练数据是成对的。图像到图像翻译是GAN很重要的一个应用方向,是基于一张输入图像得到想要的输出图像的过程,可以看做是图像和图像之间的一种映射(mapping),我们常见的图像修复、超分辨率其实都是图像到图像翻译的例子。
它基于GAN实现图像翻译,更准确地讲是基于cGAN(conditional GAN,也叫条件GAN),因为cGAN可以通过添加条件信息来指导图像生成,因此在图像翻译中就可以将输入图像作为条件,学习从输入图像到输出图像之间的映射,从而得到指定的输出图像。而其他基于GAN来做图像翻译的,因为GAN算法的生成器是基于一个随机噪声生成图像,难以控制输出,因此基本上都是通过其他约束条件来指导图像生成,而不是利用cGAN,这是pix2pix和其他基于GAN做图像翻译的差异。
如下图所示,这是它的工作流程:
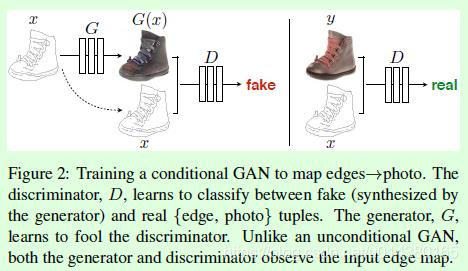
首先输入图像用y表示,输入图像的边缘图像用x表示,pix2pix在训练时需要成对的图像(x和y)。x作为生成器G的输入(随机噪声z在图中并未画出,去掉z不会对生成效果有太大影响,但假如将x和z合并在一起作为G的输入,可以得到更多样的输出)得到生成图像G(x),
然后将G(x)和x基于通道维度合并在一起,最后作为判别器D的输入得到预测概率值,该预测概率值表示输入是否是一对真实图像,概率值越接近1表示判别器D越肯定输入是一对真实图像。
另外真实图像y和x也基于通道维度合并在一起,作为判别器D的输入得到概率预测值。因此判别器D的训练目标就是在输入不是一对真实图像(x和G(x))时输出小的概率值(比如最小是0),在输入是一对真实图像(x和y)时输出大的概率值(比如最大是1)。生成器G的训练目标就是使得生成的G(x)和x作为判别器D的输入时,判别器D输出的概率值尽可能大,这样就相当于成功欺骗了判别器D。
网络设计:
生成器为典型的u-net结构

判别器采用PatchGAN,PatchGAN对输入图像的每个区域(patch)都输出一个预测概率值,相当于从判断输入是真还是假演变成判断输入的N*N大小区域是真还是假。 举个例子,假设判别器的输入是1 ∗ 6 ∗ 256 ∗ 256 ,N设置为8,判别器的输出大小是1 ∗ 1 ∗ 32 ∗ 32 ,其中32 ∗ 32 大小的输出中的每个值都表示输入中对应8 ∗ 8 区域是真实的概率。
loss设计:


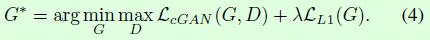
pix2pix的优化目标包含2个部分,如公式4所示。一部分是cGAN的优化目标;另一部分是L1距离,用来约束生成图像和真实图像之间的差异,这部分借鉴了其他基于GAN做图像翻译的思想,只不过这里用L1而不是L2,目的是减少生成图像的模糊。
cGAN的优化目标如公式1所示,z表示随机噪声,判别器D的优化目标是使得公式1的值越大越好,而生成器G的优化目标是使得公式1的log(1-D(x,G(x,z))越小越好,这也就是公式4中min和max的含义。这里需要注意的是正如GAN论文提到的,公式1有时候训练容易出现饱和现象,也就是判别器D很强大,但是生成器G很弱小,导致G基本上训练不起来,因此可以将生成器G的优化目标从最小化log(1-D(x,G(x,z))修改为最大化log(D(x,G(x,z))),pix2pix算法采用修改后的优化目标。
L1距离如公式3所示,用来约束生成图像G(x, z)和真实图像y之间的差异。
优缺点评论:
优点:
强监督模型,学习能力强,不需要太多数据样本就可以进行收敛,并学习到特征
缺点:
只能生成小型的图像,不能生成大的图像,比较鸡肋,同时,需要目标图像,输入的图像是一对一对的,对于没有明确目标图像的任务就没有作用
参考博文和论文
https://blog.csdn.net/u014380165/article/details/98453672
https://arxiv.org/abs/1611.07004