ROI Pooling
1, 原理
2, 实例
原理
目标检测architecture通常可以分为两个阶段:
1, region proposal:给定一张输入image找出objects可能存在的所有位置。这一阶段的输出应该是一系列object可能位置的bounding box。 这些通常称之为region proposals或者 regions of interest(ROI),在这一过程中用到的方法是基于滑窗的方式和selective search。
2, final classification:确定上一阶段的每个region proposal是否属于目标一类或者背景。
这个architecture存在的一些问题是:
产生大量的region proposals 会导致performance problems,很难达到实时目标检测。
在处理速度方面是suboptimal。
无法做到end-to-end training。
这就是ROI pooling提出的根本原因,ROI pooling层能实现training和testing的显著加速,并提高检测accuracy。该层有两个输入:
1, 从具有多个卷积核池化的深度网络中获得的固定大小的feature maps;
2, 一个表示所有ROI的N*5的矩阵,其中N表示ROI的数目。第一列表示图像index,其余四列表示其余的左上角和右下角坐标;
ROI pooling具体操作如下:
根据输入image,将ROI映射到feature map对应位置; 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同); 对每个sections进行max pooling操作; 比如某个ROI区域坐标为(x1, y1, x2, y2),那么输入size为 (y2 - y1) * (x2 - x1), 如果pooling的输出size为 poolheight * poolwidth,那么每个网格的size为

这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
实例
有一个8x8大小的feature map,一个ROI,以及输出大小为2x2.
1, 输入的固定大小的feature map

2, region proposal 投影之后位置(左上角,右下角坐标):(0,3),(7,8)
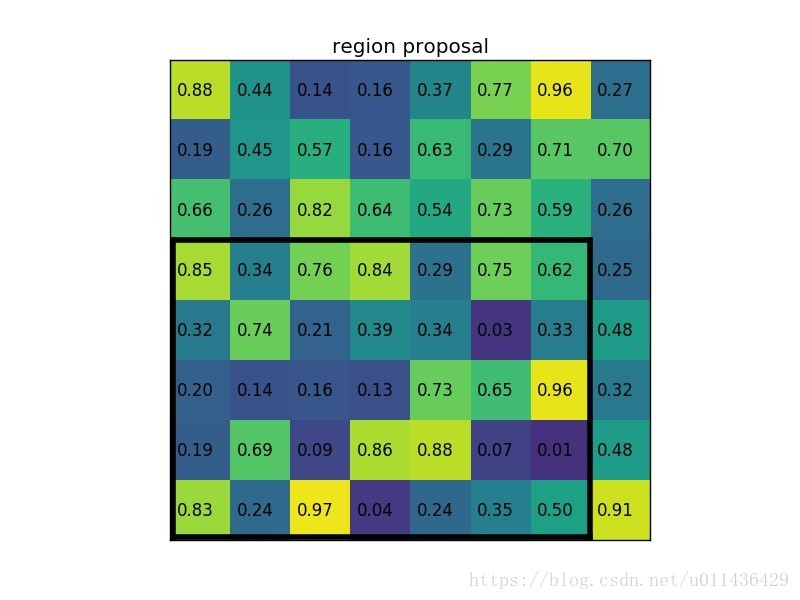
3, 将其划分为(2x2)个sections(因为输出大小为2*2), 那每个网格大小为 (5 / 2 , 7 / 2), (5 / 2, 7 / 2 + 1), (5 / 2 + 1, 7 / 2), (5 / 2 + 1, 7 / 2 + 1) 其中 5/2 表示向下取整
我们可以得到

4, 对每个section做max pooling,可以得到

参考文件
https://blog.csdn.net/u011436429/article/details/80279536
https://zhuanlan.zhihu.com/p/24780395