fpn记录, 包括以下几点
1, 原理
2, 作用
原理
FPN结构图
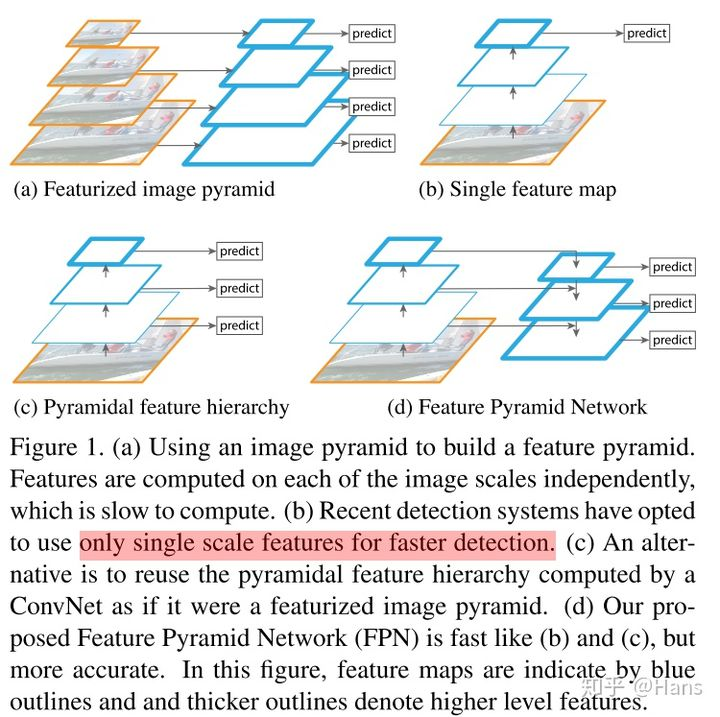
-
图(a)是传统的图像金字塔,就是把图像放缩到不同的尺度,分别进行特征提取,并进行预测,但是这种方法是十分占用内存的。
-
图(b)是单个的特征映射,就是在输入的图像上进行初步的特征提取,然后在已有的图像特征上进行下采样,逐步缩小特征,在最后一层特征上进行预测。
-
图(c)是特征金字塔结构的水平部分,就是在输入的图像上进行初步的特征提取,然后在已有的图像特征上进行下采样,逐步缩小特征,但是,在每一层特征上,都会进行一次预测,这种预测是适用于不同尺度的物体的。
-
图(d)是完整的特征金字塔结构,有3个步骤:
4.1 自下而上:就是在输入的图像上进行初步的特征提取,然后在已有的图像特征上进行下采样,逐步缩小特征。
4.2 自上而下:就是在已经提取的最上层特征进行卷积操作,得到一个特征层,然后进行上采样,对特征进行放大,同时要加上进行1x1卷积操作的之后与之同尺度的特征图。
4.3 分别预测:在经过4.2的操作之后,就要对每一张特征图分别进行预测,得到不同尺度的结果图。
对于这一原理,有2种实现方法,如下所示
网络结构图

1, Bottom-up pathway
前馈Backbone的一部分,每一级往上用step=2的降采样。
输出size相同的网络部分叫一级(stage),选择每一级的最后一层特征图,作为Up-bottom pathway的对应相应层数,经过1 x 1卷积过后element add的参考。
例如,下图是fasterRCNN的网络结构,左列ResNet用每级最后一个Residual Block的输出,记为{C1,C2,C3,C4,C5}。
FPN用2~5级参与预测(因为第一级的语义还是太低了),{C2,C3,C4,C5}表示conv2,conv3,conv4和conv5的输出层(最后一个残差block层)作为FPN的特征,分别对应于输入图片的下采样倍数为{4,8,16,32}。

2, Top-down pathway and lateral connections
自顶向下的过程通过上采样(up-sampling)的方式将顶层的小特征图。放大到上一个stage的特征图一样的大小。
上采样的方法是最近邻插值法:

使用最近邻值插值法,可以在上采样的过程中最大程度地保留特征图的语义信息(有利于分类),从而与bottom-up 过程中相应的具有丰富的空间信息(高分辨率,有利于定位)的特征图进行融合,从而得到既有良好的空间信息又有较强烈的语义信息的特征图。

具体过程为:C5层先经过1 x 1卷积,改变特征图的通道数(文章中设置d=256,与Faster R-CNN中RPN层的维数相同便于分类与回归)。 M5通过上采样,再加上(特征图中每一个相同位置元素直接相加)C4经过1 x 1卷积后的特征图,得到M4。 这个过程再做两次,分别得到M3,M2。M层特征图再经过3 x 3卷积(减轻最近邻近插值带来的混叠影响,周围的数都相同), 得到最终的P2,P3,P4,P5层特征。
作用
算法同时利用低层特征高分辨率和高层特征的高语义信息,
通过融合这些不同层的特征达到预测的效果。
并且预测是在每个融合后的特征层上单独进行的,
参考文件
https://blog.csdn.net/u014380165/article/details/72890275
http://mdsa.51cto.com/art/201707/545995.htm
https://arxiv.org/abs/1612.03144
https://zhuanlan.zhihu.com/p/92005927